[사전학습] 6.2 상관분석
상관분석
상관관계
상관관계는 변수 간의 상호 관련성을 의미하며, 관계성의 정도는 통계적 또는 시각적인 방법으로 파악가능
- 산점도
- 상관계수 (피어슨 상관계수, 스피어맨 상관계수)
산점도 (Scatter Plot)
산점도를 이용하면 상관관계를 쉽게 파악 가능
- 두 연속형 데이터의 관계 파악에 용이
- 특정 관계를 갖고 있는 데이터는 한 눈에 파악 가능
- 극단치 혹은 이상치 파악 가능
- 한 변수의 값이 증가할 때, 다른 변수의 값도 같이 증가한다면 두 변수는 양의 상관관계
- 한 변수는 증가하고 다른 변수는 감소한다면, 두 변수는 음의 상관관계
상관계수
두 변수 간의 함께 변화하는 경향을 객관적으로 측정할 수 있는 척도
- 피어슨 상관계수 => 선형관계의 강도를 측정
- 스피어맨 상관계수 비선형 순위 상관관계를 측정
피어슨 상관계수
두 변수 간 선형관계의 정도를 객관적으로 측정할 수 있는 방법
- 상관계수 r은 -1부터 1까지 값을 가짐
- 스피어맨 상관계수
- 스피어맨은 정규분포가 아니어도 monotinic(단조) 증가/하락에 관한 비선형관계 포함 가능
- log 변환
상관분석
측정된 두 변수 간의 선형관계가 있는지 탐색 및 확인하는 분석 방법
- 피어슨 상관분석
- 귀무가설
- 대립가설
- 검정 통계량 (t 검정)
- 기본 가정
- 선형성
- 정규성
- 등분산성
상관분석시 주의사항
상관관계 vs 인과관계
- 상관관계가 있다고 인과관계가 있는 것은 아님
- 인과관계가 있으면 상관관계가 있음
상관분석 Process
- Data 특성 파악 & 가설 설정
- 종속변수/독립변수 : 모두 ‘등비’여야 함
- 귀무가설 : 변수 간 선형관계 x
- 대립가설 : 변수 간 선형관계 O
- 산점도를 이용한 시각화 및 가정 검토
- 선형관계가 아니면 분석의 의미를 찾기 힘듦
- 변수별 정규성, 등분산성 체크
- 목적에 맞는 분석 수행
- Step 1 ~ 2 결과를 토대로 최종 분석 방법 선택
- 결과 해석 및 최종 결론 도출
- P값 기반 상관관계 변수 선택
- 관계의 정도 확인
실습
1
2
3
4
5
6
7
8
9
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats # 피어슨, 스피어맨 상관계수
from sklearn.datasets import load_boston
1
2
df = pd.read_csv('./data/baseball.csv')
df
산점도를 이용한 출루율(OBP)와 타율(Bat_avg) 관계 확인
1
2
sns.scatterplot(x=df['Bat_avg'], y=df['OBP'])
plt.show()
정규성 확인
Shapiro Wilk 검정을 통해 정규성 확인
1
2
print('타율의 정규성 shapiro test : ', stats.shapiro(df['Bat_avg']))
print('출루율의 정규성 shapiro test : ', stats.shapiro(df['OBP']))
1
2
sns.histplot(df['Bat_avg'])
plt.show()
1
2
sns.histplot(df['OBP'])
plt.show()
이상치 확인
1
2
sns.pairplot(df[['Bat_avg', 'OBP', 'Num_hits']])
plt.show()
이상치 제거
1
2
new_df = df.loc[df['Num_hits'] >= 50, :].copy()
new_df
1
2
print(df.shape[0])
print(new_df.shape[0])
정규성 재검정
1
2
sns.pairplot(new_df[['Bat_avg', 'OBP']])
plt.show()
1
2
print('이상치 제거 후 타율의 정규성 shapiro test : ', stats.shapiro(new_df['Bat_avg']))
print('이상치 제거 후 출루율의 정규성 shapiro test : ', stats.shapiro(new_df['OBP']))
피어슨 상관계수 산출
1
stats.pearsonr(new_df['Bat_avg'], new_df['OBP'])
비선형 순위 상관
1
boston = load_boston()
1
type(boston)
1
sklearn.utils.Bunch
1
boston.keys()
1
dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])
1
print(boston.DESCR)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
.. _boston_dataset:
Boston house prices dataset
---------------------------
**Data Set Characteristics:**
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target.
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None
:Creator: Harrison, D. and Rubinfeld, D.L.
This is a copy of UCI ML housing dataset.
https://archive.ics.uci.edu/ml/machine-learning-databases/housing/
This dataset was taken from the StatLib library which is maintained at Carnegie Mellon University.
The Boston house-price data of Harrison, D. and Rubinfeld, D.L. 'Hedonic
prices and the demand for clean air', J. Environ. Economics & Management,
vol.5, 81-102, 1978. Used in Belsley, Kuh & Welsch, 'Regression diagnostics
...', Wiley, 1980. N.B. Various transformations are used in the table on
pages 244-261 of the latter.
The Boston house-price data has been used in many machine learning papers that address regression
problems.
.. topic:: References
- Belsley, Kuh & Welsch, 'Regression diagnostics: Identifying Influential Data and Sources of Collinearity', Wiley, 1980. 244-261.
- Quinlan,R. (1993). Combining Instance-Based and Model-Based Learning. In Proceedings on the Tenth International Conference of Machine Learning, 236-243, University of Massachusetts, Amherst. Morgan Kaufmann.
분석을 위한 데이터 프레임 구성
1
2
3
X = boston.data
boston_df = pd.DataFrame(X, columns=boston.feature_names)
display(boston_df)
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 501 | 0.06263 | 0.0 | 11.93 | 0.0 | 0.573 | 6.593 | 69.1 | 2.4786 | 1.0 | 273.0 | 21.0 | 391.99 | 9.67 |
| 502 | 0.04527 | 0.0 | 11.93 | 0.0 | 0.573 | 6.120 | 76.7 | 2.2875 | 1.0 | 273.0 | 21.0 | 396.90 | 9.08 |
| 503 | 0.06076 | 0.0 | 11.93 | 0.0 | 0.573 | 6.976 | 91.0 | 2.1675 | 1.0 | 273.0 | 21.0 | 396.90 | 5.64 |
| 504 | 0.10959 | 0.0 | 11.93 | 0.0 | 0.573 | 6.794 | 89.3 | 2.3889 | 1.0 | 273.0 | 21.0 | 393.45 | 6.48 |
| 505 | 0.04741 | 0.0 | 11.93 | 0.0 | 0.573 | 6.030 | 80.8 | 2.5050 | 1.0 | 273.0 | 21.0 | 396.90 | 7.88 |
506 rows × 13 columns
1
2
boston_df['MEDV'] = boston.target
boston_df
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 501 | 0.06263 | 0.0 | 11.93 | 0.0 | 0.573 | 6.593 | 69.1 | 2.4786 | 1.0 | 273.0 | 21.0 | 391.99 | 9.67 | 22.4 |
| 502 | 0.04527 | 0.0 | 11.93 | 0.0 | 0.573 | 6.120 | 76.7 | 2.2875 | 1.0 | 273.0 | 21.0 | 396.90 | 9.08 | 20.6 |
| 503 | 0.06076 | 0.0 | 11.93 | 0.0 | 0.573 | 6.976 | 91.0 | 2.1675 | 1.0 | 273.0 | 21.0 | 396.90 | 5.64 | 23.9 |
| 504 | 0.10959 | 0.0 | 11.93 | 0.0 | 0.573 | 6.794 | 89.3 | 2.3889 | 1.0 | 273.0 | 21.0 | 393.45 | 6.48 | 22.0 |
| 505 | 0.04741 | 0.0 | 11.93 | 0.0 | 0.573 | 6.030 | 80.8 | 2.5050 | 1.0 | 273.0 | 21.0 | 396.90 | 7.88 | 11.9 |
506 rows × 14 columns
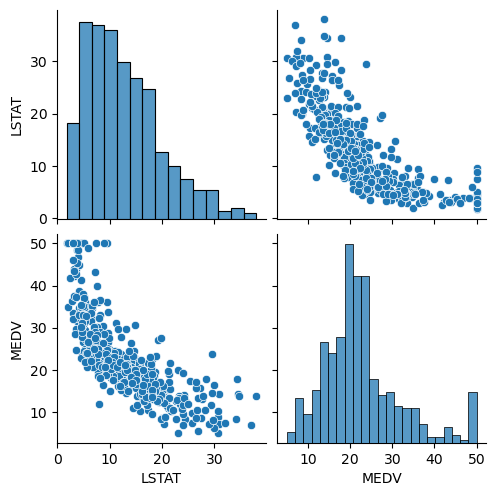
특정 지역 하위계층의 비율을 나타내는 LSTAT과 해당 지역 집값(중앙값)을 나타내는 MEDV 관계 확인
1
2
sns.pairplot(boston_df[['LSTAT', 'MEDV']])
plt.show()
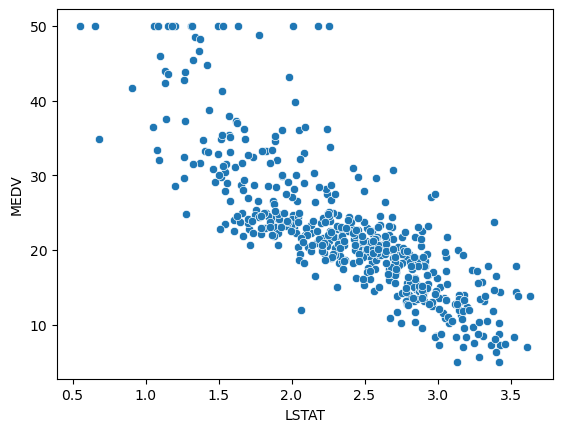
Log 변환
1
2
sns.scatterplot(x=np.log(boston_df['LSTAT']), y=boston_df['MEDV'])
plt.show()
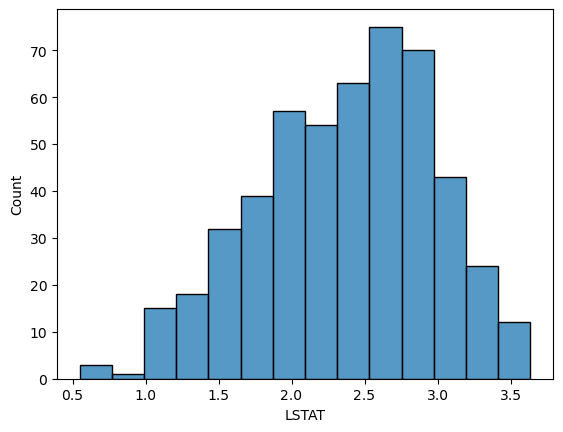
1
2
sns.histplot(np.log(boston_df['LSTAT']))
plt.show()
1
stats.shapiro(np.log(boston_df['LSTAT']))
1
ShapiroResult(statistic=0.9861650466918945, pvalue=9.793916979106143e-05)
비선형 순위 상관 스피어맨
1
stats.spearmanr(boston_df['LSTAT'], boston_df['MEDV'])
1
SpearmanrResult(correlation=-0.8529141394922163, pvalue=2.221727524313283e-144)
1
This post is licensed under CC BY 4.0 by the author.